面试突击:Redis
平时工作很多概念性的东西用不到,长时间不用吧,容易忘,但面试又确实是要问,只能复习面试的时候整理下来,也是再学习一遍。
真希望能找到一份,能把学习到的诸多理论知识变成实践的工作,而不是业务复杂,但技术不复杂的工作,嗨,加油吧。
你对Redis了解多少
如果面试要问的话可以按照一下顺序答,并把记得牢/懂得多的部分展开说,尽量连贯着说,说的全面点,让面试官无从下手打断你来问很深很难的问题(滑稽
1. 首先,Redis是非关系型数据库
有别于Mysql、Oracle、Postgresql这样传统的关系型数据库,Redis设计之初就是用来存储key-value型数据的。
key只可以是string,value只可以是string,hash,list,set,zset(有序集合)。
这边开发的时候对象一般来说建议转成json再存,直接存对象很多时候是能存的(引入的redis的jar包会帮忙转成对应的五大类型),但是一是直接存对象,在Redis里面占的空间会更大,内存可能吃不消,二是复杂的对象有可能转换不回来。
2. Redis是内存级数据库
Redis是存储在内存上的,所以先天就有读写快的优势。
不过也正因为是存储在内存上,可能因为断电等原因里面的数据就没了,所以除了对数据做容灾(十有八九会问,后面说)处理以外,并不建议将Redis作为持久化存储的数据库
3. 那同样是内存型,我们为什么不用比如guava内置的缓存,甚至直接用map结构存呢?
是因为guava和map实现的是本地缓存,生命周期绑定在了所在服务的实例上,随着现在微服务的流行,一个项目可能会有多个微服务,同一个微服务也会有多个实例,用guava和map没法做到这多个实例,多个微服务,公用一个缓存的目的
4. Redis良好的性能,除了是因为是内存级数据库以外,还因为有优秀的线程模型
Redis在都是内存级数据库里面最终脱颖而出,也是因为Redis在高并发的条件下有着更优异的性能。
Redis是单线程的,说他是单线程是因为它的核心:file event handler(文件事件处理器)是单线程的,它采用IO多路复用(也就是Java里NIO的设计思想,这里准备的好可以说,关于Java的NIO,想问的话可以一会儿说完Redis以后问,要不然会打断说Redis的思路,没做关于IO,NIO,AIO的准备这里就不要提NIO甚至不要提IO多路复用的事)来从多个socket接收事件,放入内置的队列中,再由文件事件分派器将事件分派给事件处理器
上面字太多,下面是简化版:
多个socket
–>IO多路复用
–>一个队列
–>事件分派器
–>事件处理器
因为队列天然就可以将并发削峰,一个一个处理,并且Redis本身一般来说又只是对简单数据的简单增删改查,所以单个事件的处理速度非常快,从队列里出栈的速度也非常快,所以并发就被非常巧妙的化解了
5. 而因为Redis是内存型数据库,所以它的存储空间其实远不比硬盘型数据库
那么就带来了一个问题:一直存数据,给空间装满了怎么办
所以为了解决这个问题:
5.1 在每次存数据的时候要设置过期时间
基本上就我接触过的业务而言,没什么数据是需要永不过期,还必须得存在Redis里的,所以每次存数据都要设置过期时间
5.2 但是Redis的删除策略导致了,就算设置过期时间,仍然有可能不被删掉
这里就要说一下Redis的删除策略了,Redis同时生效了两个删除策略:
5.2.1 定期删除
定期删除,顾名思义,Redis每隔一段的时间(默认是100ms),随机抽取一部分key,看过期没过期,过期了就删掉
这里这么做是因为,Redis里面可能有几十,上百万的key,要是都遍历一遍,开销得多大,100ms都不一定够用的
5.2.2 惰性删除
因为定期删除并不能把所有过期的key都删掉,所以当你从Redis里面取数据的时候,它还会判断一次这个数据过期了没,没过期就返给你,过期了就清掉,然后告诉你没了(明明是有的!他不给我),这就相当于主动触发删过期数据了
5.3.3 内存淘汰机制
可是惰性删除仍然不能完全解决,如果你的业务上写多,读少,那终究有一刻还是会把一开始Redis占用的内存空间给占满的,所以Redis有内存淘汰机制来确保最终不会影响使用(仍然不代表所有过期的key都会被删掉)
这里最重要,最常用的是这个:
allkeys-lru,当内存空间不足以写入新数据时,移除【最近】【最少】使用的key。
触发次数最少(只在内存空间不足时触发,不是定时触发),需要遍历/删除的东西也少,不会有很大的性能开销
在Redis4.0后又新增了一个淘汰机制,也是我觉得比较好的:
allkeys-lfu,当内存空间不足以写入新数据时,移除【最少】使用的key。
比上面的优点是,触发以后删的更干净,那触发次数会更好,缺点是,触发的时候性能开销更大,各有利弊,我觉得都不错
还有其他的机制,因为感觉不是很重要,看一看能记住几个算几个吧:
volatile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰
volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰
volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰
allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰
no-eviction:禁止驱逐数据,也就是说当内存不足以容纳新写入数据时,新写入操作会报错。这个应该没人使用吧!
下面这个是4.0和上面推荐的第二个一起新加的
volatile-lfu:从已设置过期时间的数据集(server.db[i].expires)中挑选最不经常使用的数据淘汰
6. 刚才说到Redis可是持久化来容灾,那接下来就说一下这个持久化
Redis主要有两种持久化方案:快照型和日志型
6.1 快照型(RDB)
快照型是Redis默认开启的持久化方案,是需要触发的,触发一次会全量保存一次数据。
默认有三种触发方式同时生效:
- 900秒里,有一个key变动,保存快照
- 300秒里,有十个key变动,保存快照
- 60秒里,有一万个key变动,保存快照
优点:开销小,触发了才有开销。并且理论上相当于冷备份了,可以上传至文件服务器或者其他方案永久保存,用来追溯一些东西也是挺好的。
缺点:占用空间大,理论上丢数据可能丢的多,如果60秒内改动了9999个数据,结果Redis挂了,这9999个数据就丢失了,不可恢复
6.2 日志型(AOF)
日志型,日志型现在最为主流,需要手动开启。
就相当于存两份,内存里一份,硬盘上一份,Redis在内存里每变化一条数据,在硬盘上也同时变化一条。
不过这样如果读写的快,硬盘IO会跟不上的,所以一般AOF用的是每秒一同步的策略,丢了最多丢一秒
实际上在线上环境,在性能/空间允许的情况下,两种可以都开
在4.0以后,还有混合型,AOF每次写的时候可以写整个压缩后的快照,不过这样优点是加载快,丢的东西少,缺点是性能开销更大
7. Redis作为数据库,也是支持事务的
但是由于Redis的内存型数据库,所以作为事务的传统4要素,ACID,其中持久化,实现的比较特殊,之前已经说过了,和传统的关系型数据库实现的持久化不太一样。
并且,关于原子性的理解,Redis官方的理解是“**Either all of the commands or none are processed, so a Redis transaction is also atomic.**”,就是说命令要么都执行,要么都不执行。但是都执行了,执行没成功抛出异常了,然而前面执行成功的部分又不会回滚,官方认为还是执行了的,只是后面没成功而已嘛。
我个人认为这并不太原子性。。。emmm,每个人有每个人的看法嘛
这里有一种情况:如果一个事务里,有多个命令,其中后面一个命令,压根这个命令就是错的命令,并不是执行出错的那种,是压根没法执行的时候,在执行事务的时候前面正确的命令也不会生效,不过这是回滚么?我觉得不是,应该是执行的时候对事务内的命令检查了一下,命令错了就都不执行,压根前面正确的就没执行,怎么能说是回滚呢
8. 那说了这么多Redis,我们为什么要用Redis呢
一般来说,Redis是用在读多写少的业务场景,将常用的读数据缓存起来,用来缓解数据库压力的
但是不管是Redis也好,还是用别的方案也好,都会面对一个核心问题:缓存命中率上不去怎么办
这个核心问题衍生了几个常见问题:
8.1 缓存雪崩
由于之前说的Redis删除机制其实是并不可控的,尤其是常用的内存淘汰机制是有可能把还没到过期时间,过去一段时间用的不多的数据给删了。但是用的不多不代表就不用,只是没高频的高而已,一下子大面积删了,导致这些零星的请求一下子打到数据库去了,虽然一个缓存的请求量不多,但是删的多了量就上去了,数据库扛不住了,这就是缓存雪崩
要解决缓存雪崩:集群式部署Redis实例,哪个实例宕机了及时恢复
8.2 缓存穿透
比如由于攻击者大量的构建了很多虚拟的key也好,比如像微博热点那样以前完全没料到,然后一下子爆了大量的相关的搜索,之前压根就没缓存相关key也好,比如代码写的时候设计有问题,完全就没缓存到一部分key也好,总之大量的请求压根就没缓存,穿过了Redis直接到了数据库里面,一下给数据库弄崩溃了
这两个归根结底都是因为缓存没拦住请求,缓存命中率低,导致过多的读请求直接到了数据库,给数据库弄崩了(现代架构最脆弱的最麻烦的就是数据库了,前端也好,后端也好,都可以多部署实例来分流,并且现在技术很成熟了,除了钱以外并不花特别多的成本,但是数据库扛不住了要改造,这可不是只是多花钱多布几台服务器的事了,整个后端逻辑很多部分都要重新改造)
要解决缓存穿透:应对性的缓存空key,或者用布隆过滤器过滤非法请求
8.3 缓存击穿
因为热点key过期了,然后由于惰性删除,一取就直接过期了,导致瞬间高并发一下子到数据库那里了,这就是缓存击穿
要解决缓存击穿:设置热点key永不过期,或者上互斥锁
同时,在设计上也应该做好:
- redis集群部署,多部署几台不至于大面积雪崩。
- 后端做好熔断限流,最大程度保住数据库。
- 做好预警工作,当缓存命中率低于阈值且集群的内存使用率高出阈值要及时发出警报。
9. 那既然Redis的主要作用是缓存,那只要是缓存就都有一个小问题
那就是数据一致性的问题。
数据库和缓存,一定会有个先后问题,比如先改了数据库,然后再同步到缓存。或者比如并发大的统计操作,先在缓存里加减,隔多少时间定期写回到数据库,这些情况都挺常见的。一般只要用缓存都会有或多或少的数据一致性的问题。
如果说业务上没那么高的数据一致性的要求,这样是最好的,效率最高。
如果产品经理就非得要做,那我的理解是就只好把修改的时候,把修改数据库和修改Redis放到spring的一个事务里面去,确保要更新就一起更新,但还是建议产品经理想想有没有别的方案,因为这么一搞,只要写的操作不是那么少,Redis的效率就会低很多
上面说完关于Redis就已经说了很多了,希望面试官能没有耐心听,跳到下一个知识点去,真要问下面的,就说这些只是略知皮毛,不知道其原理,一般都是架构组决定,运维来实施,确实不知道原因是什么
Redis为了实现高可用,有哪些部署模式
1. 主从模式
从节点复制主节点的信息
2. 哨兵模式
定义了一个或多个哨兵,对Redis的节点进行监控,如果主节点挂了可以从其他子节点自动升级成主节点,哨兵是需要提前配置的,需要把各个节点的信息写在哨兵的配置文件里,所以要是节点多的话好像写起来麻烦,不太好做水平扩展
3. 集群模式
集群模式的话就是集群的节点互相监控,自己推举主节点,这个好像更好一些,我以前公司用的这种方式
Redis的zset,底层用的什么数据结构
用的跳表,因为Redis的作者觉得,在单线程下,用跳表实现起来比红黑树简洁
这篇文章讲的非常好:https://www.cnblogs.com/liang1101/p/12984881.html
跳表的原理大概是,一个更优的,用在链表上的二分法,因为二分法适用于有序数组,但是有序链表压根就没有下标,那二分没法定位啊,取第几个就得遍历几次,这效率远不如直接遍历
所以跳表就通过层数来解决,每次新增一个元素的时候决定它从下往上数增了几层,50%一层,25%两层,12.5%三层,等等,最大32层,这样理论上只有一层的元素数达到2的64次方个数的时候才会有元素随机到32层
示意图如下:
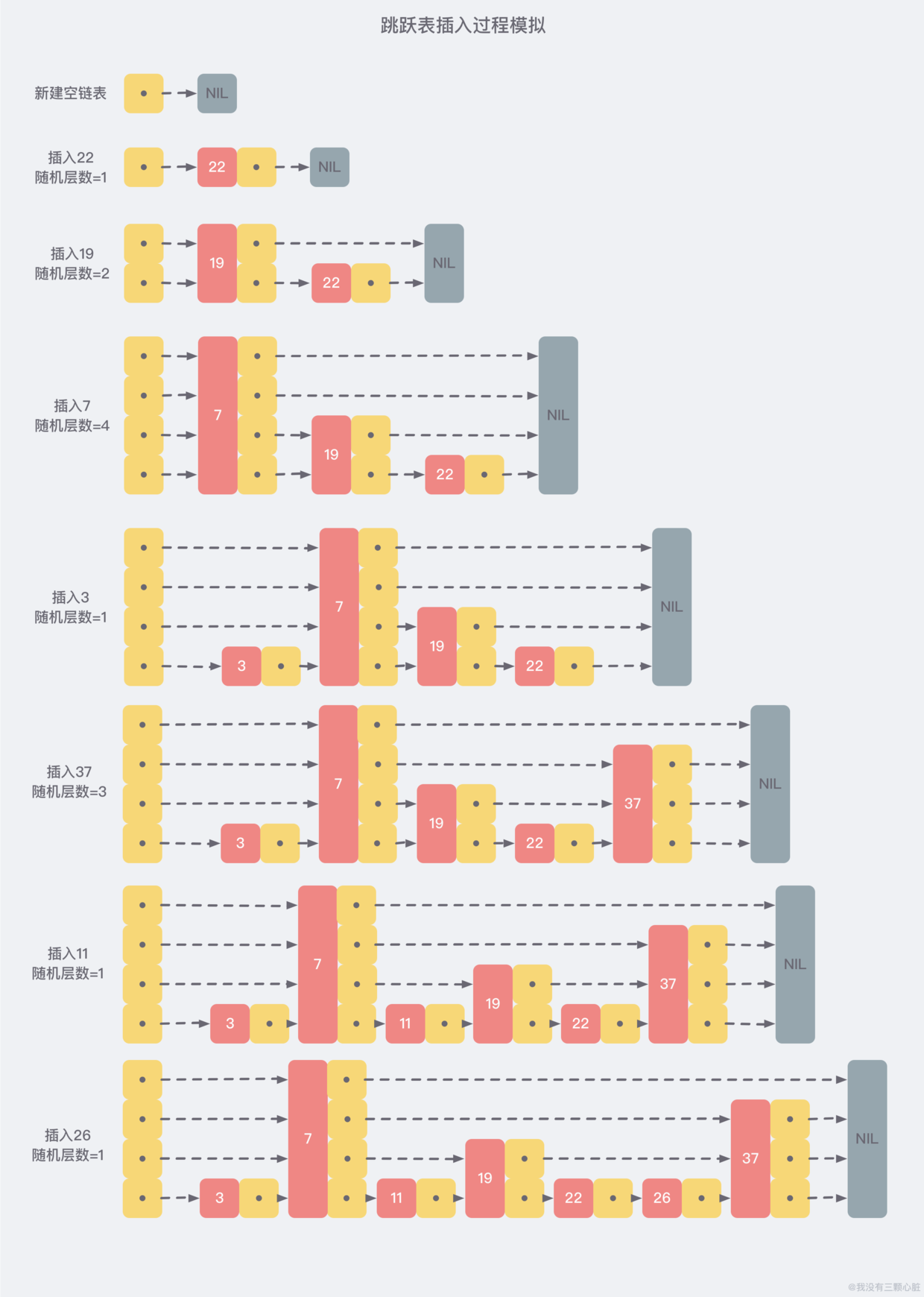
然后找和插入的时候从上往下找,就类似于二分了,比如想往里插23:
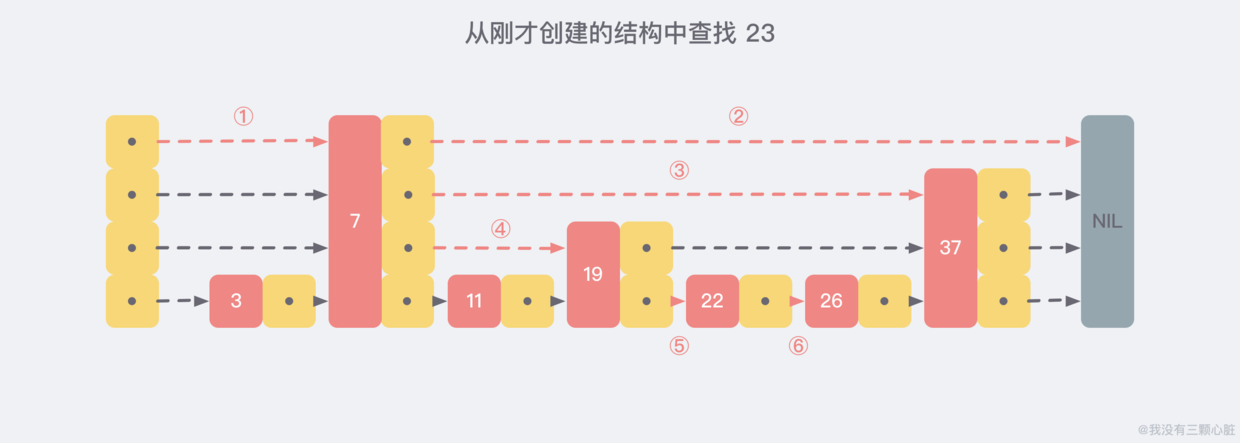
从最上面一次找到最下面一层,就找到了
让手写源码?写不出来,告辞
