突击面试:Mysql
平时工作很多概念性的东西用不到,长时间不用吧,容易忘,但面试又确实是要问,只能复习面试的时候整理下来,也是再学习一遍。
真希望能找到一份,能把学习到的诸多理论知识变成实践的工作,而不是业务复杂,但技术不复杂的工作,嗨,加油吧。
事务隔离级别
说事务隔离级别之前需要先弄明白三个概念:脏读、不可重复读、幻读
脏读
现在并发了俩事务,第一个事务先修改了一条数据,然后第二个事务进来读了这条数据,结果刚读完,第一个事务回滚了,数据库里还是数据之前的状态了,那你第二个数据读到的内容对不对?肯定不对啊,这就是读了脏数据
要解决脏读,需要让事务不能读取到其他未提交的事务所影响的数据就可以了,也就是事务隔离级别的:Read Committed
不可重复读
还是并发了俩事务,第一个事务先读了一行,然后第二个事务进来给这行修改了/删除了,然后第二个事务结束了,提交了,执行完了。然而第一个事务还没完,第一个事务因为业务需要又读了一次,结果这同一个事务中,重复读同一行数据两次,结果却不一样,这就是不可重复读。不可重复读这一现象是否正确,要取决于业务场景
要做到可重复读,需要在这个事务执行的时候锁住这一行,其他的事务没法操作不就没事了么,也就是事务隔离级别的:Repeatable Read
幻读
依然是并发了俩事务,第一个事务比如说,删表跑路了,直接delete table 没加 where ,然后第二个事务往表里插入了一条数据,这俩事务执行完以后第一个事务一看:不对啊,我明明都删了啊,这多的那条哪来的?我出现了幻觉?影响了删表跑路的进程,这仿佛幻觉一样的一条,就是幻读。幻读这一现象是否正确,要取决于业务场景
所以要做到不幻读,那读的时候行锁就没用了,得把整个表给锁住,也就是事务隔离级别的:Serializable
💡所以不可重复读和幻读最大的区别,同样也就是Repeatable Read和Serializable的区别,就是锁行和锁表的区别,解决不可重复读是锁行,所以不可重复读是修改/删除导致的,解决幻读要锁表,所以幻读是新增导致的
理解了这仨东西,那事务隔离级别理解起来就更简单了,就是为了避免出现这仨东西出来的,看下面这图就知道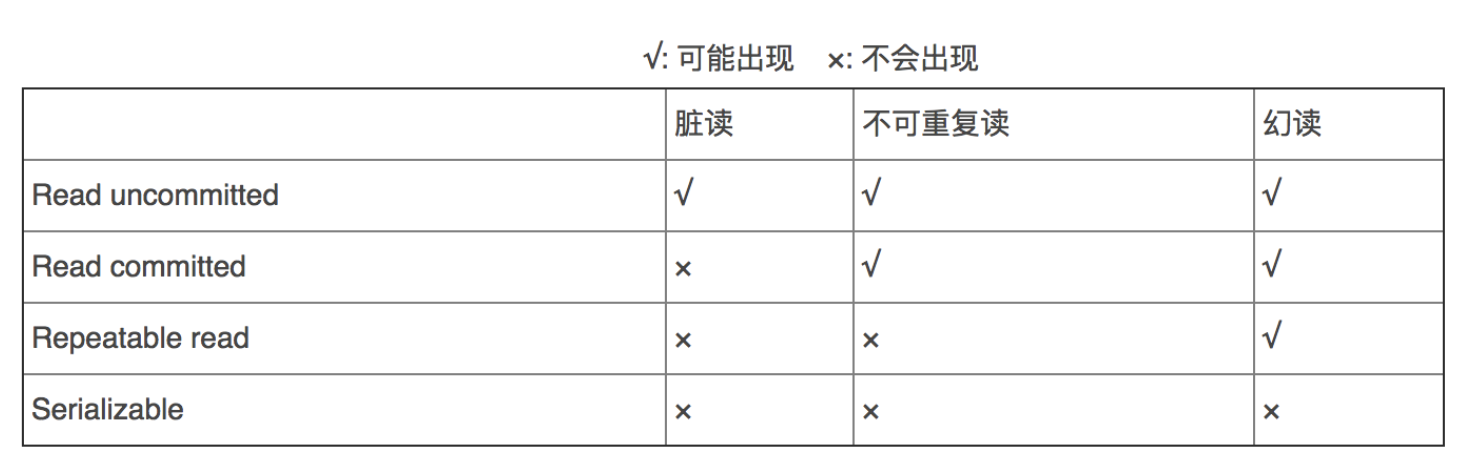
1. Read Uncommitted(读未提交)
可以读取其他事务没提交的内容
2. Read Committed(读提交)
Oracle的默认隔离级别。只能读别的事务已经提交的内容
3. Repeatable Read(重复读)
Mysql的默认隔离级别。同一个事务中,对同一行多次读的内容是相同的
4. Serializable(序列化)
最高隔离级别。所有事务操作依次顺序执行。注意这会导致并发度下降,性能最差。通常会用其他并发级别加上相应的并发锁机制来取代它。
💡 因为3有行锁,4有表锁,所以一般来说隔离级别越高,性能越差
索引
一种优化查询的数据结构,就像字典的目录一样,提前帮数据建好目录,查找的时候就快很多,简单的说就是空间换时间
建索引本身需要开销的,时间开销和空间开销。
时间开销体现在:插入会变慢一点点,并且如果有大量的数据的表的话,这时候新建索引会锁表(长事务执行,阻塞建索引语句获取metadata独占锁,继而所有同表的语句都被阻塞了),那如何解决锁表问题呢,嗨,业务要求没那么高,可以停机维护的,就停机维护的时候再加索引,业务要求高了,就得先备份,再加索引,再替换回来。
空间开销嘛,就不谈了,加索引肯定要占空间
索引的种类
hash索引,B+树,最常见,还有完全平衡二叉树,B树,用的不多,甚至很多工具比如Navicat上都没法选,不打算了解
hash索引
是对那一列对值做了hash,所以是精准匹配,不适用于需要like这样搜索的查询,并且对在硬盘上是否连续存放没啥关系,所以如果是用在查比如UUID上,会很合适
完全平衡二叉树
就是有序的二叉树,支持范围查找,基本上远不如B+树,不考虑用
B+树和B树
这俩的共同点是:都可以在树的节点存储多个元素,和完全平衡二叉树一样都是天然有序,所以范围查询不需要全表扫描
这俩的区别是:B+树的子节点存储了所有的父节点,并且子节点之间用指针连接。B树在父节点上也存了数据,B+树只在子节点上存了数据。
所以一看就明白,B树和B+树因为存储了多个元素,所以更适合做范围查询,并且B+树更像是图了,不仅仅是树的结构,所以检索次数更少,磁盘IO也就更少了,效率更高
聚簇索引和非聚簇索引(辅助索引)
建表的时候,一般会建个ID作为主键,这个主键就是聚簇索引
聚簇索引最主要的特点是,这个索引整行的数据都存放在子点节点上,一张表只能有一个聚簇索引
而辅助索引是除了索引列以外,还包含了聚簇索引键(也就是主键),然后再根据聚簇索引键再回表查那一行的数据
也就是说一般来说,非聚簇索引会比聚簇索引多查一次,效率会低一些
但是有特殊情况,比如说如果要查的列恰好就只是辅助索引的内容,那就直接返回就行了,不用再回表查别的数据了,这个又叫覆盖索引
联合索引
因为最左前缀匹配的原则,要把where中最经常用的放在左边
因为如果建了一个联合索引(1,2,3),实际上数据库里会多三个索引:(1),(1,2),(1,2,3),但是没有(2,3)的索引,所以如果where里面没有1的话,就不走索引了
查看sql执行情况
用explain查看执行计划
为什么有时候明明建了索引,但是执行的时候却没有通过索引呢
如果不是因为索引没有覆盖到的话,那可能是因为查询优化器认为不走索引效率更高
查询优化器的工作大致流程:
- 根据搜索条件,找出所有可能使用的索引
- 计算全表扫描的代价
- 计算使用不同索引执行查询的代价
- 对比各种执行方案的代价,找出成本最低的那一个
被索引字段如果是函数,则不会走索引
如果select的字段有1234,而123有索引,且有一个是like ‘%param%’有左百分号时,由于要回表+最左匹配的原则会导致全表扫,不走索引
但是如果select字段123,索引也是123,不管是不是模糊查询都不会回表,会走索引
乐观锁和悲观锁
乐观锁
乐观锁嘛,顾名思义,就比较乐观,觉得一般来说读不会有问题,只在增删改的时候加锁,适用于读多写少的情况
悲观锁
就挺悲观的,咋着都会出问题,在读的时候就会加锁,适用于读少写多的情况,确保不会发生冲突
乐观锁的实现方式
1. CAS
无锁算法,会有ABA问题,想解决ABA问题的话就要加版本号
2. 版本号
每次写入的时候要判断读的version和数据库现有version是否相同,相同的话version要+1,写入。不相同的话就尝试更新
acid
acid就是四个特性的英文首字母,数据库必须满足这四个特性才算是支持事务
原子性(Atomicity)
事务中的操作,要么都执行,要么都不执行
一致性(Consistency)
保证不论这时候并发有多少个,都不能扰乱事务正常执行,确保系统处于一致状态
有点绕,不知道怎么表达,就比如说一个数据库里2条记录,A账户和B账户各100块,总共200块,然后疯狂执行事务,让他们两个账户互相转钱,不管多少个事务,不管并发有多少,在任何一个时间点AB账户的总和都应该是200块,不因为并发执行在某一刻出现问题
隔离性(Isolation)
就是确保相同的功能,在同一时刻只能有一个事务正常执行(不同的功能可以并行)
持久性(Durability)
事务执行完以后要持久化的体现在数据库里,不会没了,丢了,回滚了
MVCC
多版本并发控制(Multi-Version Concurrency Control)
顾名思义,就是乐观锁的版本号方法,一个事务取数据的时候顺便把version取了,另一个事务也来取这条数据的时候,如果没有MVCC,那就要加排他锁,第二个事务只能等第一个事务执行完了才能读的到。但是有了MVCC,第二个事务也可以来读,读的时候也拿到了version,然后谁先操作完了谁给version+1写回去,后写的人发现持有的version和数据库里现有的对不上了,就更新了再操作。虽然消耗了一些性能和运算量,但是比干等着锁来的快啊!
比如:数据库读可提交的实现一般都用的MVCC,每次个事务来读都相当于创建一个带版本号的副本
数据库优化
这里因为没有实际操作经验,就只能谈谈理论上能做的
- 判断是否由于硬件原因导致,如CPU使用率满了导致偶发性的慢查询
- 数据上千万以后,超出了innodb_buffer的容量,导致每次定位索引会做更多的磁盘IO操作,所以设计之初就应该用雪花这样的有序id作为聚簇索引,保证数据在存放时在磁盘上是连续的,减少IO开销
- explain查看是否没能正确设置索引
- 业务允许的前提下,先限定查询区间,禁止全表扫
- 垂直拆分,将一个业务表拆成俩业务表,比如list表和detail表
- 读写分离
- 水平拆分,比如用户表,根据用户创建的年份每年一个表,然后用sharding这样的工具去查
- 分库,不同的业务拆分至不同的数据库(物理机)
- 建议重构,用HBASE,MYSQL里只留id等类似于索引的数据,然后根据id集去HBASE里查
